No hay mejor forma de empezar el año que con una nueva edición del encuentro anual Aporta sobre el estado de la reutilización de los datos públicos en España, organizado por el Ministerio de Industria, Energía y Turismo, el Ministerio de Hacienda y Administraciones Públicas y la Entidad Pública Red.es.
Este año el encuentro estuvo dedicado al valor de los datos abiertos y contó también con la novedad de incorporar un foro sectorial sobre los datos de turismo. Además, tuve el placer y privilegio de compartir mesa con Antonio Rodriguez (Jefe del Área de Infraestructura GIS en el Instituto Geográfico Nacional de España), Aleida Alcaide (Consejera Técnica del Ministerio de Hacienda y Administraciones Públicas) y Jose Luis Roda (Profesor titular de la Universidad de la Laguna) como moderador de una sesión con un tema de lo más interesante: la Calidad e Interoperabilidad de los datos.

El planteamiento que realicé como hilo conductor de la mesa seguía tres premisas básicas que me gustaría compartir:
1 – Los problemas de calidad e interoperabilidad no son una novedad de los datos abiertos
La calidad de los datos y la interoperabilidad son dos retos importantes que no son nuevos en absoluto y llevan con nosotros desde el inicio de las TIC e incluso mucho antes. Ahora sin embargo, gracias a la proliferación de iniciativas de datos abiertos, los datos están cada vez más expuestos y los reutilizadores comienzan a verlos con nuevas y diferentes perspectivas distintas a las originales. Los datos son puestos a prueba, se analizan, se visualizan y se buscan nuevas utilidades y servicios que hacen aflorar también nuevos problemas no detectados hasta el momento, aumentando al mismo tiempo el grado de exigencia de calidad.
Quien piense que sus datos no tienen ningún problema es que no los ha mirado nunca con suficiente detenimiento.
Todo analista de datos experimentado ha aprendido a convivir con cierto grado de error e incertidumbre en los datos como parte natural e inevitable del proceso; y también han aprendido a planificar los proyectos adecuadamente incluyendo el esfuerzo y los procedimientos necesarios para el tratamiento de esos errores.
2 – La calidad total de los datos es una “quimera” que debemos perseguir
Sin embargo, al contrario que los analistas, los “propietarios” o gestores de los datos sienten habitualmente una cierta resistencia natural a la aceptación de los errores, mucho más cuando ahora son expuestos “públicamente”. Debido a ello necesitan cierto periodo de aceptación y durante la última reunión del comité de dirección del Open Data Institute, Tim Berners-Lee comparaba este proceso con las 5 etapas del trauma descritas por el modelo Kübler-Ross:
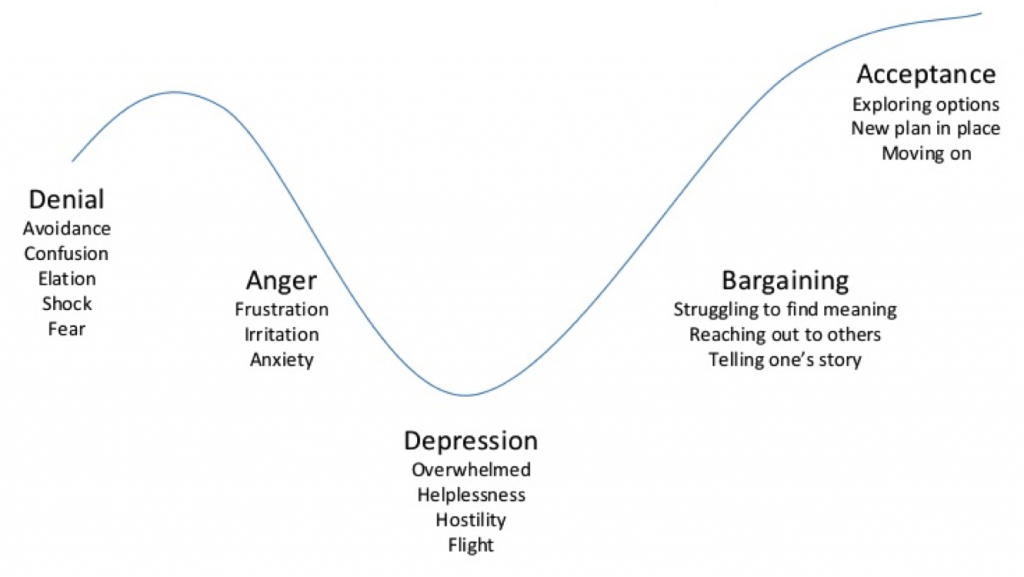
- Negación: Los datos no pueden estar mal, el problema tiene que estar en otro sitio.
- Ira: ¿Quién es el responsable y por qué no nos habíamos dado cuenta hasta ahora?
- Regateo o Negociación: ¿Podemos ignorar y ocultar los fallos de alguna manera?
- Depresión: En realidad estos datos están tan mal que no servirán para nada. Sería mejor dejarlo.
- Aceptación: De acuerdo, sabemos que hay un problema. Documentémoslo y describamos el alcance y las limitaciones.
Una vez superadas las etapas anteriores es necesaria la transición hacia una etapa adicional de “Esperanza” en la que finalmente nos damos cuenta de que, gracias a que los datos están ahora más expuestos, podemos contar también con más ayuda, mejores herramientas y canales de feedback para poder corregir los problemas y usarlos en nuestro beneficio para mejorar la calidad final.
3 – Las tres vertientes de la interoperabilidad.
Podemos descomponer la problemática de la interoperabilidad de los datos en tres componentes principales.
Interoperabilidad Técnica

En este nivel hablamos de infraestructuras, protocolos y tecnologías utilizadas para compartir datos de forma común para que los sistemas puedan hablar entre sí.
Este punto generalmente no suele resultar especialmente conflictivo, al contar ya con una base de infraestructuras y tecnologías en Internet y la Web suficientemente maduras y adecuadas para este fin. No obstante la creación de frameworks específicos y adecuados para cubrir las necesidades de este tipo de proyectos puede ayudar a facilitar considerablemente el uso y aprovechamiento de los datos. Un ejemplo en esta línea sería el proyecto Europeo FI-WARE que explota el concepto cada vez más extendido de las Open APIs.
Interoperabilidad Semántica
 Aquí nos centramos en que los sistemas sean capaces no únicamente de hablar, sino de entenderse entre ellos. Está vertiente se encuentra a medio camino entre la parte más técnica y la más humana, y será la capa encargada de facilitar los estándares adecuados para la representación de los datos y la información, de forma que pueda analizarse e intercambiarse automáticamente, pero al mismo tiempo mantenga también su capacidad de poder ser comunicada a las personas de forma comprensible para ellos.
Aquí nos centramos en que los sistemas sean capaces no únicamente de hablar, sino de entenderse entre ellos. Está vertiente se encuentra a medio camino entre la parte más técnica y la más humana, y será la capa encargada de facilitar los estándares adecuados para la representación de los datos y la información, de forma que pueda analizarse e intercambiarse automáticamente, pero al mismo tiempo mantenga también su capacidad de poder ser comunicada a las personas de forma comprensible para ellos.
Interoperabilidad Sintáctica o Humana
 Este último componente se centra en las personas que tienen que llegar a acuerdos y convenios para “hablar el mismo idioma” – ¿Qué es el Open Data? ¿Qué principios sigue? ¿Cómo se hace “bien”? ¿Qué datos hay que abrir? ¿Con qué estándar y en qué formato? ¿Qué modelo deben seguir unos determinados datos? ¿Sirve un único modelo para todo el mundo?
Este último componente se centra en las personas que tienen que llegar a acuerdos y convenios para “hablar el mismo idioma” – ¿Qué es el Open Data? ¿Qué principios sigue? ¿Cómo se hace “bien”? ¿Qué datos hay que abrir? ¿Con qué estándar y en qué formato? ¿Qué modelo deben seguir unos determinados datos? ¿Sirve un único modelo para todo el mundo?
Poner a todo el mundo de acuerdo para dar respuesta común a estas preguntas es quizás el reto más grande, y más difícil será aún cuanto más global es el objetivo, ya que a los retos propios del Open Data tenemos que unir aquellos relacionados con el Big Data o la Internacionalización (en ambas vertientes: globalización y localización) y el reto del Broad Data.
En esta parte se están centrando actualmente múltiples grupos de trabajo en organizaciones tan diversas como el G8, el Grupo del Open Data del Open Government Partnership, la iniciativa de Interoperabilidad de la Comisión Europea, la Global Open Data Initiative, la actividad de Datos del W3C, etc.
Calidad e interoperabilidad en tres casos de uso.
Las intervenciones de mis compañeros de mesa se centraron en explicar la necesidad y los beneficios de las acciones para asegurar la calidad e interoperabilidad de los datos en tres casos de uso distintos y a cada cual más interesante: La directiva Inspire, la actualización de la Directiva Europea de Reutilización de la Información y el proyecto Open Data Canarias.
Sus intervenciones y la del resto de las mesas del encuentro, así como entrevistas y otros materiales audiovisuales pueden consultarse en el mini-site temático SpainESData.
http://www.slideshare.net/datosgob/aporta2014-sesin-maana
Open Data: de la transparencia al negocio
Esta es la entrevista que me hicieron para el artículo sobre las posibilidades de negocio del Open Data en el último número de la revista Fundetec y publicada también en Infotics.
La posibilidad de que tanto los ciudadanos como las empresas puedan acceder y utilizar los datos almacenados por las administraciones está permitiendo el nacimiento de un nuevo modelo de negocio basado en la creación de productos y servicios de valor añadido a partir de esta información pública.
Los expertos afirman que brindan un sinfín de posibilidades a los usuarios y desarrolladores para crear múltiples aplicaciones y negocios en la red.
P1 – ¿ Nos podía concretar alguna de esas posibilidades?
Desde mi punto de vista el verdadero potencial reside en el hecho de que por mucho que se intente no creo que haya nadie capaz de concretar esas posibilidades, y eso es debido a que el concepto de la innovación aplicado al Open Data se basa principalmente en dos premisas:
- El principio de las muchas mentes:
“La mejor forma de explotar tus datos se le ocurrirá siempre a otro” – Jo Walsh y Rufus Pollock.
- La Ley de Joy:
“No importa quien seas, la personas más brillantes trabajan siempre para otros” – Bill Joy.
Sumando ambas premisas es cuando nos damos cuenta de que las posibilidades residen precisamente en unir la apertura de los datos con la creatividad de aquellos que los vayan a combinar y transformar para poder ser utilizados. No existen fórmulas mágicas, la clave fundamental sigue siendo la misma de siempre, pensar en cuáles son las necesidades de las personas y buscar la mejor manera posible de poder satisfacerlas, la única diferencia es que ahora tenemos la oportunidad de poder acceder cada día a más datos y a nuevas fuentes como las que proporcionan las redes sensoriales de las Smart Cities, lo que multiplica las posibilidades.
P2 – En este momento en España ¿Cuáles son las principales iniciativas y fuentes de datos en abierto disponibles?
En España contamos ya con unas veinte iniciativas a todos los niveles. A nivel nacional tenemos no sólo el Catálogo Nacional de Datos, sino también con cierto marco legislativo, una serie de planes estratégicos en desarrollo, guías prácticas, un marco de interoperabilidad para la reutilización de recursos de la información y otras medidas de apoyo con el objetivo de conseguir que el número de conjuntos de datos disponibles vaya aumentando gradualmente tanto en cantidad como en calidad.
A nivel regional existen también múltiples iniciativas, desde las pioneras en Euskadi, Asturias o Cataluña hasta la más reciente en Aragón, y a nivel local ciudades como Zaragoza y Gijón fueron las encargadas de abrir un camino al que se han ido sumando otras como las recién incorporadas Pamplona y Terrassa.
Pero lo más importante es que el Open Data sigue muy vivo y no hay prácticamente un mes en el que no se anuncie otra iniciativa. En lo poco que llevamos de año ya llevamos cuatro nuevas iniciativas y seguiremos sumando, porque estoy convencido que este será el año de las iniciativas en las ciudades y comenzaremos a ver cada vez más a lo largo del mundo.
P3 – ¿Cómo y para qué pueden utilizar las empresas estos datos?
Todas las empresas utilizan datos en mayor o menor medida para su actividad diaria. La variedad de datos y su potencial es tan grande que el límite en cuanto a sus posibilidades de aplicación lo pone únicamente la imaginación.
Algunos datos son de aplicación más transversal, como la Información Geográfica y la Meteorología, y por tanto pueden ser de utilidad prácticamente para cualquier empresa o negocio. Otros datos pueden tener nichos de explotación mucho más específicos como por ejemplo los datos relacionados con la sanidad o las investigaciones clínicas, pero aun así al tratar cuestiones de claro interés público pueden dar lugar también a servicios con un mercado potencial muy amplio.
P4 – ¿Cuáles son los datos más utilizados y a partir de ellos qué servicios están surgiendo?
Los datos que suscitan un mayor interés suelen ser aquellos relacionados con Información Geográfica y Cartografía, Información Económica, Jurídica y Legal, Estadística y Sociodemografía, Transportes, Sanidad, Educación, Empleo, Seguridad, etc.
Sin embargo, no todos están siempre disponibles, así que dependiendo del país y el caso concreto los datos más utilizados pueden ser unos u otros. En principio, los datos relacionados con la Información Geográfica son con diferencia los más demandados y al mismo tiempo los más utilizados a nivel global, a lo que contribuye sin duda que las estimaciones indican que aproximadamente un 80% de las decisiones que deben tomar tanto las autoridades públicas como las grandes empresas cuentan con un componente geoespacial. Por otro lado ese éxito es debido también en buena parte a la directiva INSPIRE, que ha conseguido proporcionar un marco común para las infraestructuras del ámbito geoespacial a nivel Europeo, dando así lugar al caldo de cultivo ideal para el éxito en la reutilización.
P5 – ¿Es difícil usarlos?
Conseguir que los datos estén disponibles, y que además se publiquen bajo unas condiciones de uso que permitan su reutilización es ya un gran paso. Sin embargo, en muchos casos el tratamiento de los datos resulta un proceso bastante más costoso de lo que sería razonable debido a que no se publican de la forma adecuada. Esto da lugar a que se tenga que invertir tiempo y recursos en su tratamiento que serían mucho más productivos si se utilizasen para el análisis posterior, que es la parte del proceso donde realmente se genera valor.
Utilizar formatos que sean legibles por las máquinas, adoptar vocabularios estandarizados para los datos y documentarlos adecuadamente son acciones imprescindibles para facilitar la reutilización, eliminar barreras de entrada a nuevas empresas para que puedan crear sus productos o servicios y conseguir que exista un mercado de datos vivo y dinámico.
P6 – ¿Hay que tener conocimientos específicos o una base tecnológica para utilizarlos?
La gran variedad de datos existente, las posibilidades que ofrecen los múltiples formatos disponibles y la proliferación de herramientas que facilitan o incluso automatizan en parte su tratamiento hacen que hoy en día prácticamente cualquiera pueda experimentar con los datos si se lo propone y le dedica un poco de tiempo.
Por supuesto, cuanto más complejos sean los datos o el análisis que queramos realizar sobre ellos mayores serán también los conocimientos específicos que debemos tener para poder sacarles partido, y es ahí donde surge la necesidad de todo un mercado especializado de intermediarios de datos o infomediarios.
No hay que olvidar que el análisis y tratamiento de los datos es toda una ciencia por sí misma, que de hecho se viene denominando “Data Science”, y que implica la participación de múltiples y variados perfiles para poder exprimirle todo el jugo a los datos, desde profesionales de las matemáticas y la estadística hasta especialistas en algoritmos de tratamiento de datos o expertos en su visualización, pasando por supuesto por las personas capacitadas para el estudio de la materia específica que se esté analizando en cada caso, ya sea sanidad, educación, transportes, etc.,
Y es que no es lo mismo hacer una aplicación para móvil que nos indique cuáles son las farmacias de guardia que proponerse realizar un estudio sobre el genoma humano por ejemplo. Aunque en ambos casos estaremos creando nuevos productos y servicios útiles para la sociedad y basados en el Open Data, los conocimientos requeridos, los medios necesarios para llevarlos a cabo y los beneficios obtenidos en uno y otro caso serán obviamente muy distintos.
P7 – En este momento ¿Qué número de empresas han desarrollado en nuestro país algún servicio a partir de estos datos públicos?
Ese es un dato que es difícil de estimar, debido a que no se cuenta con ningún censo oficial de referencia, y el hecho de que nuestro registro mercantil sea un conjunto de datos completamente cerrado tampoco ayuda a facilitar este tipo de análisis.
En el caso de España se suele tomar como referencia el estudio del sector infomediario realizado por el ONTSI, que en su última edición realizó un censo de más de 150 empresas en el sector. Sin embargo, mi propia experiencia me indica que es mucho más que probable que la realidad del mercado sea considerablemente mayor, ya que el censo utilizado no es exhaustivo y existe todo un mercado paralelo de actividades relacionadas con los datos que actualmente no se recogen y que es difícil de cuantificar.
Por otro lado, nos encontramos en una fase en la que el mercado está todavía tomando forma, y una vez se empiecen a poner en marcha medidas adicionales que aporten mayor seguridad y sostenibilidad al sector, como por ejemplo la unificación de las licencias de uso o la aplicación de compromisos de servicio que garanticen la disponibilidad de los datos y eliminen la incertidumbre para los emprendedores que quieran montar sus servicios sobre unos determinados datos.
P8 – ¿Qué volumen de negocio generan?
Se han realizado varios estudios a nivel internacional al respecto y, aunque las cifras no siempre coinciden, lo que sí que tienen todos en común es que las estimaciones son siempre optimistas y los volúmenes de negocio son realmente considerables.
En el caso de España nuevamente podemos tomar como referencia inicial el estudio del ONTSI que hace unas estimaciones de un volumen de negocio de unos 500 millones de euros para el conjunto del sector. Sin embargo es más que probable que la realidad del mercado sea considerablemente mayor, ya que al hecho de que el censo de empresas no sea exhaustivo hay que sumarle que no se exploran en profundidad posibles sinergias con otros sectores. Por ejemplo, la Asociación Multisectorial de la Información (ASEDIE) hace unas estimaciones de cifras de negocio en torno a 50.000 millones de euros si tenemos en cuenta también las potenciales sinergias entre el Open Data y la industria de los contenidos digitales, lo que podría llegar a suponer hasta un 5% del PIB nacional.
Además, en muchos casos los modelos de negocio todavía no están claramente definidos y se siguen explorando las posibilidades, por lo que a medida que el mercado vaya alcanzado también una mayor madurez en ese sentido es previsible que eso se haga notar también en el volumen de negocio.
Por supuesto, e independientemente de todas estas cifras económicas, tampoco podemos olvidar que gracias al Open Data se generan también otra serie de valores intangibles para la sociedad como mejoras en la transparencia del Gobierno y la participación de los ciudadanos.
P9 – Territorialmente ¿En qué Comunidad Autónoma hay un mayor grado de reutilización de esta información o mayor número de empresas?
Dado que Internet y las Nuevas Tecnologías son los habilitadores que facilitan las tareas de compartir y analizar grandes cantidades de información es un hecho que las empresas cuya base de negocio consiste en la reutilización de datos suelen tener también un componente tecnológico considerable. Como es lógico entonces, se detecta también una mayor concentración de empresas reutilizadoras allí donde también se encuentra una mayor concentración de empresas con estas características, es decir principalmente Madrid y Cataluña.
En cuanto a los lugares dónde se puede concentrar más la reutilización yo diría que el interés por los datos es global y por tanto no creo que exista tal concentración, si bien como es evidente en cada caso el grado de reutilización será directamente proporcional a la cantidad de información disponible, el valor de los datos publicados y el ecosistema de reutilizadores que se forme a su alrededor. Si tenemos en cuenta esas tres variables quizás podamos destacar nuevamente a Cataluña, puesto que cuenta ya con un gran número de iniciativas que publican algunos datos realmente interesantes y con un completo ecosistema de reutilización vivo, activo y coordinado, elementos que en su conjunto a día de hoy no encontramos todavía en ninguna otra región.
P10 – La Comisión Europea ha estrenado este año su nuevo portal de datos abiertos en el que quiere que participen todos sus organismos ¿Puede suponer esto el definitivo impulso para este sector de contenidos que llaman infomediario?
El portal que recientemente ha publicado la Comisión Europea para facilitar el acceso a la información de sus propias instituciones es un nuevo paso hacia delante dentro de la política global que lleva ya a cabo desde hace algunos años para fomentar la reutilización de la información de los organismos públicos.
Dentro de esa misma política de promoción del Open Data en el ámbito Europeo, está previsto también que este mismo año salga a concurso un nuevo portal pan-europeo en el que los distintos países miembro puedan federar sus datos formando así un macrocatálogo de información pública a nivel europeo, así como con otras medidas que incluyen acciones para la publicación de más conjuntos de datos y el fomento de las tecnologías de datos enlazados o la difusión y sensibilización en el sector público a través de la renovación de la ePSI Platform.
Desde luego todas estas medidas son pasos positivos para el impulso de la economía en torno al Open Data, ya que supondrán una mayor disponibilidad de datos de alto valor y en un formato que facilite su explotación, pero en mi opinión el impulso más importante y puede que definitivo será la puesta en marcha de la Incubadora Open Data Europea, que de forma similar al trabajo realizado por el Open Data Institute en el Reino Unido, trabajará para facilitar a las empresas los datos que necesitan y los medios para poder llevar a cabo sus proyectos. Espero que algún día podamos ver esos mismos modelos replicados también en España, puesto que creo que las medidas relacionadas con el Gobierno Abierto y el Open Data incluidas en la Agenda Digital van por el camino correcto, pero echo también en falta otras actuaciones que las complementen.
Actualización – Desde la realización de esta entrevista se han producido un par de novedades importantes que tienen mucho que ver con lo que en ella se comenta:
- La revisión de la Directiva Europea de Reutilización de la Información del Sector Público.
- El anuncio de que el programa Open Data Support se hará cargo de llevar a la práctica el federador de datos a nivel Europeo utilizando el estándar de interoperabilidad DCAT-AP.