No hay mejor forma de empezar el año que con una nueva edición del encuentro anual Aporta sobre el estado de la reutilización de los datos públicos en España, organizado por el Ministerio de Industria, Energía y Turismo, el Ministerio de Hacienda y Administraciones Públicas y la Entidad Pública Red.es.
Este año el encuentro estuvo dedicado al valor de los datos abiertos y contó también con la novedad de incorporar un foro sectorial sobre los datos de turismo. Además, tuve el placer y privilegio de compartir mesa con Antonio Rodriguez (Jefe del Área de Infraestructura GIS en el Instituto Geográfico Nacional de España), Aleida Alcaide (Consejera Técnica del Ministerio de Hacienda y Administraciones Públicas) y Jose Luis Roda (Profesor titular de la Universidad de la Laguna) como moderador de una sesión con un tema de lo más interesante: la Calidad e Interoperabilidad de los datos.

El planteamiento que realicé como hilo conductor de la mesa seguía tres premisas básicas que me gustaría compartir:
1 – Los problemas de calidad e interoperabilidad no son una novedad de los datos abiertos
La calidad de los datos y la interoperabilidad son dos retos importantes que no son nuevos en absoluto y llevan con nosotros desde el inicio de las TIC e incluso mucho antes. Ahora sin embargo, gracias a la proliferación de iniciativas de datos abiertos, los datos están cada vez más expuestos y los reutilizadores comienzan a verlos con nuevas y diferentes perspectivas distintas a las originales. Los datos son puestos a prueba, se analizan, se visualizan y se buscan nuevas utilidades y servicios que hacen aflorar también nuevos problemas no detectados hasta el momento, aumentando al mismo tiempo el grado de exigencia de calidad.
Quien piense que sus datos no tienen ningún problema es que no los ha mirado nunca con suficiente detenimiento.
Todo analista de datos experimentado ha aprendido a convivir con cierto grado de error e incertidumbre en los datos como parte natural e inevitable del proceso; y también han aprendido a planificar los proyectos adecuadamente incluyendo el esfuerzo y los procedimientos necesarios para el tratamiento de esos errores.
2 – La calidad total de los datos es una “quimera” que debemos perseguir
Sin embargo, al contrario que los analistas, los “propietarios” o gestores de los datos sienten habitualmente una cierta resistencia natural a la aceptación de los errores, mucho más cuando ahora son expuestos “públicamente”. Debido a ello necesitan cierto periodo de aceptación y durante la última reunión del comité de dirección del Open Data Institute, Tim Berners-Lee comparaba este proceso con las 5 etapas del trauma descritas por el modelo Kübler-Ross:
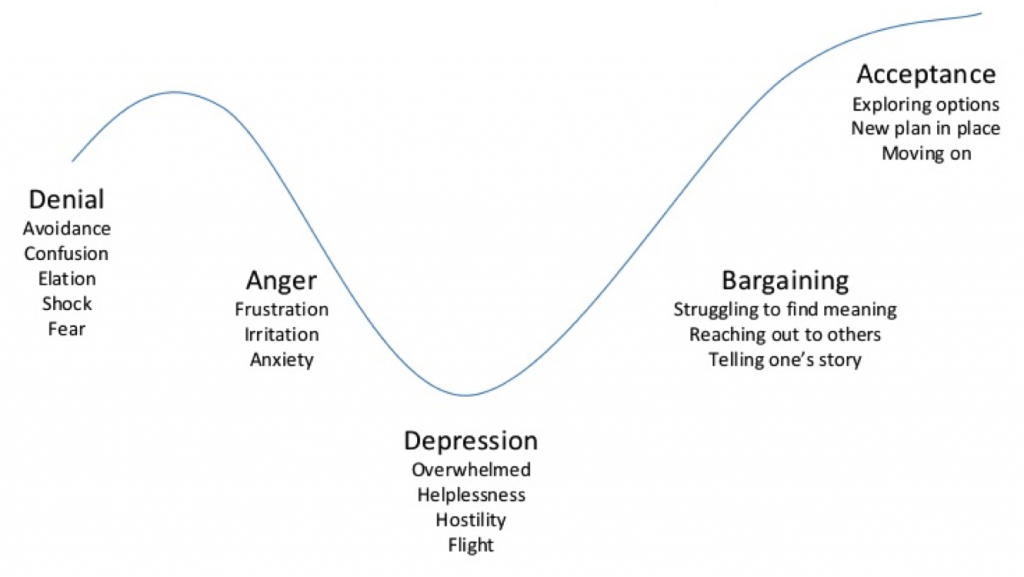
- Negación: Los datos no pueden estar mal, el problema tiene que estar en otro sitio.
- Ira: ¿Quién es el responsable y por qué no nos habíamos dado cuenta hasta ahora?
- Regateo o Negociación: ¿Podemos ignorar y ocultar los fallos de alguna manera?
- Depresión: En realidad estos datos están tan mal que no servirán para nada. Sería mejor dejarlo.
- Aceptación: De acuerdo, sabemos que hay un problema. Documentémoslo y describamos el alcance y las limitaciones.
Una vez superadas las etapas anteriores es necesaria la transición hacia una etapa adicional de “Esperanza” en la que finalmente nos damos cuenta de que, gracias a que los datos están ahora más expuestos, podemos contar también con más ayuda, mejores herramientas y canales de feedback para poder corregir los problemas y usarlos en nuestro beneficio para mejorar la calidad final.
3 – Las tres vertientes de la interoperabilidad.
Podemos descomponer la problemática de la interoperabilidad de los datos en tres componentes principales.
Interoperabilidad Técnica

En este nivel hablamos de infraestructuras, protocolos y tecnologías utilizadas para compartir datos de forma común para que los sistemas puedan hablar entre sí.
Este punto generalmente no suele resultar especialmente conflictivo, al contar ya con una base de infraestructuras y tecnologías en Internet y la Web suficientemente maduras y adecuadas para este fin. No obstante la creación de frameworks específicos y adecuados para cubrir las necesidades de este tipo de proyectos puede ayudar a facilitar considerablemente el uso y aprovechamiento de los datos. Un ejemplo en esta línea sería el proyecto Europeo FI-WARE que explota el concepto cada vez más extendido de las Open APIs.
Interoperabilidad Semántica
 Aquí nos centramos en que los sistemas sean capaces no únicamente de hablar, sino de entenderse entre ellos. Está vertiente se encuentra a medio camino entre la parte más técnica y la más humana, y será la capa encargada de facilitar los estándares adecuados para la representación de los datos y la información, de forma que pueda analizarse e intercambiarse automáticamente, pero al mismo tiempo mantenga también su capacidad de poder ser comunicada a las personas de forma comprensible para ellos.
Aquí nos centramos en que los sistemas sean capaces no únicamente de hablar, sino de entenderse entre ellos. Está vertiente se encuentra a medio camino entre la parte más técnica y la más humana, y será la capa encargada de facilitar los estándares adecuados para la representación de los datos y la información, de forma que pueda analizarse e intercambiarse automáticamente, pero al mismo tiempo mantenga también su capacidad de poder ser comunicada a las personas de forma comprensible para ellos.
Interoperabilidad Sintáctica o Humana
 Este último componente se centra en las personas que tienen que llegar a acuerdos y convenios para “hablar el mismo idioma” – ¿Qué es el Open Data? ¿Qué principios sigue? ¿Cómo se hace “bien”? ¿Qué datos hay que abrir? ¿Con qué estándar y en qué formato? ¿Qué modelo deben seguir unos determinados datos? ¿Sirve un único modelo para todo el mundo?
Este último componente se centra en las personas que tienen que llegar a acuerdos y convenios para “hablar el mismo idioma” – ¿Qué es el Open Data? ¿Qué principios sigue? ¿Cómo se hace “bien”? ¿Qué datos hay que abrir? ¿Con qué estándar y en qué formato? ¿Qué modelo deben seguir unos determinados datos? ¿Sirve un único modelo para todo el mundo?
Poner a todo el mundo de acuerdo para dar respuesta común a estas preguntas es quizás el reto más grande, y más difícil será aún cuanto más global es el objetivo, ya que a los retos propios del Open Data tenemos que unir aquellos relacionados con el Big Data o la Internacionalización (en ambas vertientes: globalización y localización) y el reto del Broad Data.
En esta parte se están centrando actualmente múltiples grupos de trabajo en organizaciones tan diversas como el G8, el Grupo del Open Data del Open Government Partnership, la iniciativa de Interoperabilidad de la Comisión Europea, la Global Open Data Initiative, la actividad de Datos del W3C, etc.
Calidad e interoperabilidad en tres casos de uso.
Las intervenciones de mis compañeros de mesa se centraron en explicar la necesidad y los beneficios de las acciones para asegurar la calidad e interoperabilidad de los datos en tres casos de uso distintos y a cada cual más interesante: La directiva Inspire, la actualización de la Directiva Europea de Reutilización de la Información y el proyecto Open Data Canarias.
Sus intervenciones y la del resto de las mesas del encuentro, así como entrevistas y otros materiales audiovisuales pueden consultarse en el mini-site temático SpainESData.
http://www.slideshare.net/datosgob/aporta2014-sesin-maana
Interoperabilidad de los catálogos Open Data Europeos
Se acaba de abrir el plazo de comentarios y revisión pública del borrador de la especificación para el perfil de Aplicación de DCAT destinado a mejorar la interoperabilidad de Catálogos Open Data en la Unión Europea.
El perfil de aplicación de DCAT para portales Open Data Europeos (DCAT-AP) es una especificación para describir mediante metadatos los conjuntos de datos del sector público, de forma que se esas descripciones puedan ser compartidas entre diferentes catálogos o agregadas en un único punto de acceso común. La especificación forma parte del programa ISA de soluciones de interoperabilidad para Administraciones públicas Europeas de la Comisión Europea, dentro de la iniciativa Joinup de interoperabilidad semántica.

DCAT-AP toma como base principal el Vocabulario de Catálogos de Datos (DCAT) – estándar definido por el W3C que ya está siendo utilizando en varios Catálogos tanto en España como en Europa – así como otros vocabularios de referencia como ADMS o Dublin Core. Los objetivos principales de la especificación son:
- Identificar los elementos esenciales de DCAT para el contexto Europeo.
- Identificar los vocabularios comunes que se utilizarán como referencia en el contexto Europeo.
- Identificar el conjunto mínimo de metadatos para el intercambio de información entre catálogos Open Data en Europa.
DCAT-AP indica los metadatos mínimos necesarios para cumplir con las necesidades de los catálogos Open Data proporcionando así un mecanismo de interoperabilidad semántica con otras aplicaciones. Es también importante destacar que, si bien DCAT-AP está desarrollado bajo el modelo de RDF, la intención es definir únicamente el formato de intercambio y no el entorno operativo del catálogo, por lo cual también podrá ser utilizado en entornos que no implementen una solución Linked Data completa.
- Otros perfiles de aplicación – entre los que se incluye la Norma Técnica de Interoperabilidad de Reutilización de recursos de la información – y modelos de descripción de conjuntos de datos que están siendo ya utilizados en Europa y que han servido como input para este trabajo.
- Diferentes escenarios y casos de uso de ejemplo para la aplicación de DCAT-AP.
- Vocabularios de referencia propuestos para su utilización de forma conjunta con el perfil de aplicación.
- Aspectos de accesibilidad y multilingüismo que se deberán tener en cuenta.
- Cuestiones relacionadas con el entorno de despliegue de DCAT-AP.
Participa
La definición de DCAT-AP se lleva a cabo a través del consenso de un grupo internacional de expertos que participan en distintas iniciativas Open Data de la Unión Europea. No obstante, el Vocabulario se encuentra ahora en fase de revisión pública durante las próximas cuatro semanas y es muy importante que todos los interesados revisen la especificación y comenten sus impresiones para entre todos poder conseguir la máxima interoperabilidad tanto por parte de los proveedores de datos como de los potenciales consumidores.
También se puede consultar el historial de las distintas cuestiones que se han ido debatiendo a lo largo del desarrollo del perfil de aplicación.
Interoperabilidad y Reutilización de Recursos de la Información
Recientemente se ha publicado la norma técnica de interoperabilidad de reutilización de recursos de la información en España, en la que he tenido el privilegio de poder participar, y que forma parte del Esquema Nacional de Interoperabilidad. La publicación de esta norma supone un hito importante, ya que en ella se establecen las condiciones comunes sobre selección, identificación, descripción, formato, condiciones de uso y puesta a disposición de los documentos y recursos de información elaborados o custodiados por el sector público.
![]()
El objetivo de esta norma es facilitar y garantizar el proceso de reutilización de la información de carácter público procedente de las Administraciones públicas en todos los niveles, asegurando la persistencia de la información, el uso de formatos así como los términos y condiciones de uso adecuados.
La norma ha sido diseñada teniendo en cuenta en todo momento los principios del Open Government Data e incluye instrucciones detalladas sobre:
- El esquema de identificadores únicos para los datos que exponen públicamente.
- Metadatos de los documentos y recursos de información catalogados.
- Taxonomía de sectores primarios donde se especifican los temas relacionados a cada uno de ellos.
- Identificadores correspondientes a los recursos geográficos del territorio español.
También está disponible una guía de aplicación de la Norma con el objetivo de servir como herramienta de apoyo para la aplicación e implementación de lo dispuesto en la misma.
[Actualización: Se han publicado también algunas correcciones al documento original de la Norma Técnica de Interoperabilidad]